Pattern playback, a device that converts a spectrographic representation back to a speech signal, was developed by Cooper and his colleagues from Haskins Laboratories in the late 1940s and has contributed tremendously to the rapid development of research in speech science (Cooper et al., 1951, 1952; Borst, 1956). Today, we can easily implement a modern pattern playback with digital technology, and this is valuable for pedagogical applications (Arai et al., 2005, 2006).
The following algorithm is based on the fast Fourier transform (FFT). In this algorithm, a time slice of a given spectrogram is treated as a logarithmic spectrum of that time frame, and the spectrum is converted back into the time domain by the inverse FFT as shown in Fig. 1. Because we are not reconstructing the original phase, we simply set the phase components to zero.
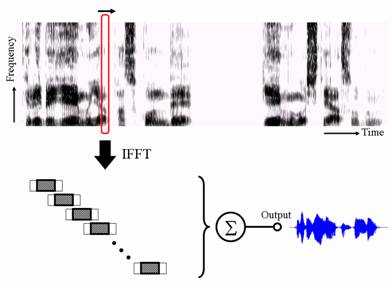
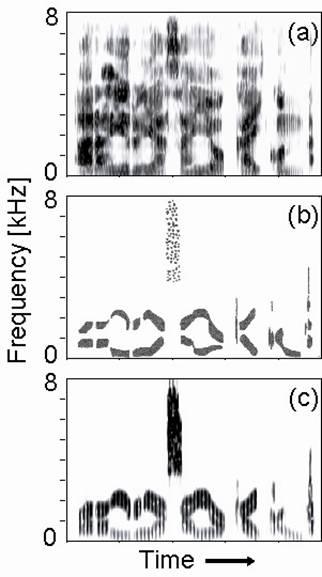
Figure 2 (a) shows the spectrogram of an original speech signal (56 kB). From Fig. 2 (a), we obtained a reconstructed speech signal (76 kB) using the FFT-based algorithm. Figure 2 (b) is a simplified version of the original spectrogram (a), and Fig. 2 (c) is the spectrogram of a reconstructed signal (76 kB) from the simplified version using the FFT method. In this case, the sampling frequency was 16 kHz, the frame length was 16 ms, and the frame shift was 10 ms (the fundamental frequency was 100 Hz).
Spectrograms (and any images) can be converted into sounds. Please send us an image file to the following e-mail address: arai@sophia.ac.jp.
The digital pattern playback system converts the file into a sound file, and we will send it back to you.
The frequency range of the spectrogram should be 0-8 kHz;
the ideal duration of the utterance is about 2-3 seconds.
- Arai, T., Yasu, K. and Goto, T., “Digital pattern playback,” Proc. Autumn Meet. Acoust. Soc. Jpn., 429-430, 2005.
- Arai, T., Yasu, K. and Goto, T., “Digital pattern playback: Converting spectrograms to sound for educational purposes,” Acoust. Sci. & Tech., 27(6), 393-395, 2006.
- Borst, J. M., “The use of spectrograms for speech analysis and synthesis,” J. Audio Eng. Soc., 4, 14-23, 1956.
- Cooper, F. S., Liberman, A. M. and Borst, J. M., “The interconversion of audible and visible patterns as a basis for research in the perception of speech,” PNAS, 37, 318-325, 1951.
- Cooper,F. S., Delattre, P. C., Liberman, A. M., Borst, J. M. and Gerstman, L. J., “Some experiments on the perception of synthetic speech sounds,” J. Acoust. Soc. Am., 24 (6) , 597-606, 1952.