Phonation begins with air flowing from the lungs, setting the vocal folds into motion, and generating a glottal sound. The vocal folds are the two flaps of tissue located on the left and right side of the larynx, and the term glottis refers to the gap between the vocal folds. When the glottal sound propagates in the vocal tract, it is modified by the resonance characteristics of the vocal tract. The sound is then emitted from the lips and/or nose, and we hear speech sounds, or phonation. The various types of phonation, such as modal, breathy, and creaky voice are distinguished by the respective degree of glottal closure.
Due to the physiology of the vocal tract, it is impossible to isolate the sound produced at the glottis, but many studies propose models to approximate this sound.
The glottal volume velocity, or $U_{ \mathrm{g} }(t)$, which is the volume velocity of the air passing through the glottis, looks like the following:
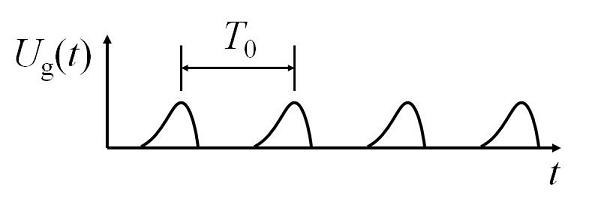
As shown in this figure, the waveform is a series of asymmetric triangular shapes, with distance in between. When the glottis starts to open, the air flow gradually increases, and the air flow rapidly decreases when the glottis closes. The simultaneous closure of the vocal folds along the length of the folds produces the sharp edges in the waveform, as the air flow suddenly stops. The sharp edges produce rich harmonic components in the higher frequencies. In this figure, $T_{0}$ corresponds to the period of vocal fold vibration, and its reciprocal, or $f_{0}$, is the fundamental frequency.
The vocal folds of adult females and children are shorter and thinner, and they vibrate faster as compared to adults males. As a result, an average $f_{0}$ for adult males is around 100 or 120 Hz, whereas the fundamental frequencies of adult females and children are double that, or higher.
A device called an artificial larynx is often used as a prosthesis for patients who have had their larynx removed due to disease. There are two types of artificial larynx: one is the electrolarynx, and the other is powered by the patient’s own breath. As an example of the latter type, the Japanese group, Hanko-kai, has manufactured a whistle-type artificial larynx (see photo).

- Kent, R. D. and Read, C., Acoustic Analysis of Speech, Singular Publishing, San Diego, CA, 2001.
- Arai, T., “Education system in acoustics of speech production using physical models of the human vocal tract,” Acoustical Science and Technology, 28(3), 190-201, 2007.
- Stevens, K. N., Acoustic Phonetics, Cambridge, MA, MIT Press, 1998.