1. Arai’s model
Arai [2] proposed two types of models: the cylinder-type model with the precise reproduction of the original vocal-tract shapes by Chiba and Kajiyama [1], and the plate-type model which is a step-wise approximation of the same original shapes. In both cases, a vowel-like sound is produced from the lip end when a sound source is excited at the glottis end.


1.1 Cylinder-type model
In Chiba and Kajiyama (1942) [1], polygonal lines show the radius for five Japanese vowels based on their measurements. These lines are the first-order approximation of the original measurements. This type of approximation may introduce some loss of speaker-specific spectral information while still maintaining vowel quality. We used the same approximations because we also wish to show speaker-independent aspects of vowel production. Therefore, we used the polygonal lines of the radius along the length of the vocal tract. The cylinder-type (or round bottle-shaped) models were produced by means of rotating these radius curves around a pivot.
For the cylinder-type model we made an acrylic cylinder with a diameter of 50 mm. The resin was sculpted from the center of the cylinder so that the cavity formed a round bottle-shape. Prior to sculpting the cavity we cut each cylinder into a couple of portions in order to reach the less accessible areas of the cavity with the sculpting tool. Finally, we glued the portions of the cylinder together.
1.2 Plate-type model
An easier way to make a similar vocal tract model is to use the zeroth-order approximation of the radius curves. We approximate the radius curves at 10 mm resolution in a step-wise fashion. The plate-type model consists of a set of acrylic plates, each with a hole in the center. When placed side-by-side the holes in the plates form a tube, the cross-sectional area of which changes in a step-wise fashion. Each plate is 75 mm x 75 mm x 10 mm. The following tableshows the diameters of the holes varying based on the zeroth-order approximation with a 10 mm resolution of the radius curves.
Table: Diameters along the length of vocal tract from the lips (left) to glottis (right) the in mm.
| Vowel | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| /i/ | 24 | 14 | 12 | 10 | 10 | 10 | 16 | 24 | 32 | 32 | 32 | 32 | 32 | 32 | 12 | 12 |
| /e/ | 24 | 22 | 22 | 20 | 18 | 16 | 16 | 18 | 24 | 28 | 30 | 30 | 30 | 30 | 12 | 12 |
| /a/ | 32 | 28 | 30 | 34 | 38 | 38 | 34 | 30 | 26 | 20 | 14 | 12 | 16 | 26 | 12 | 12 |
| /o/ | 14 | 22 | 26 | 32 | 38 | 38 | 34 | 28 | 22 | 16 | 14 | 16 | 22 | 30 | 12 | 12 |
| /u/ | 16 | 14 | 20 | 22 | 24 | 26 | 22 | 14 | 18 | 26 | 30 | 30 | 30 | 30 | 12 | 12 |
2. Source-filter theory of vowel production
The process of vowel production can be modeled a linear combination of the vocal tract as a linear time-invariant (LTI) system, the glottal sound source as an input signal to the system, and radiation characteristics as shown in the following figure.
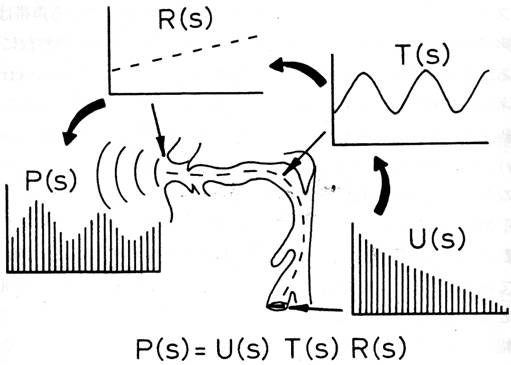
In this figure, the vowel spectrum P(s) is the product of the spectrum of the glottal source U(s), the transfer function of the vocal tract T(s) (i.e., filter), and the radiation characteristics R(s). This model is also known as “source-filter theory” of vowel production [21].
Source-filter theory is easily taught with the vocal tract models. To demonstrate this theory, we begin by producing sounds from a source. In this step, we especially have to make sure that it is a buzz-like sound, such as that emitted at the actual glottis, having no vowel quality, but it produces our sensation of the pitch. Once we input the sound source into a vocal tract model for a vowel, we can show students that the quality of the sound has changed, that it now has vowel quality, but the pitch has not changed. By feeding several different sound sources into a model, we can demonstrate that pitch and voice quality are determined by the sound source (vocal folds vibration), not by the shape or type of model (vocal tract). At the same time, students are able to see that the quality of a vowel is determined by the shape of the resonator (vocal tract) independent of the sound source (vocal folds vibration). Finally, we are able to show students that harmonic structure is independent of the resonance of the acoustic tube.
3. Education in Acoustics using the vocal tract models
3.1 Sound sources
3.1.1 Electrolarynx
To excite any vocal tract, we need a sound source. An electrolarynx is a good candidate for the sound source, because it produces a reasonably clear vowel sound through the models. The electrolarynx a device for patients for laryngectomy to simulate a glottal source. The electrolarynx itself is an effective tool for education in speech science, because students can observe that the original buzz sound of the electrolarynx changes immediately to a human-like vowel when the device is gently pressed on the outside of the neck, just opposite the larynx. (Vowel production is most effectively demonstrated when the glottis is closed but not vibrating.)
3.1.2 Whistle-type artificial larynx
As an alternative sound source, a whistle-type artificial larynx is also available.

3.1.3 Lung models
The whistle-type artificial larynx requires airflow to produce sounds. The easiest way to provide airflow during a demonstration is to blow into the whistle-type larynx. Alternatively, bellows may be used. Bellows may be preferable, in order to avoid giving students the incorrect impression that a person is phonating a vowel rather than simply blowing into the device. In this sense, bellows are useful because they are not impacted by or confused by human anatomy.
To imitate the human respiratory system with a simple device, we adopted a functional model of the lung and diaphragm [22-24]. With this model, we can slowly pull on the knob attached to the “diaphragm” (a rubber membrane covering the bottom of the cavity) to inflate the “lungs” (represented by two balloons). The two balloons are connected to a Y-shaped tube, which simulates the trachea. Lowering the diaphragm increases the volume of the thoracic cavity thereby creating negative pressure in the air inside of the thoracic cavity. Air flows into the lungs to equalize the pressure inside the lungs with the atmospheric pressure, and this simulates inhalation. Pushing up on the diaphragm decreases the thoracic cavity volume, causing air to flow out of the lungs, simulating exhalation.




[Video of the large lung model 1 (818 kB)]
[Video of the large lung model 2 (1,266 kB)]
[Video of the small lung model (276 kB)]
3.2 The relationship between vocal-tract shape and vowel quality
The following figure shows the midsaggital cross-section for each of five Japanese vowels.
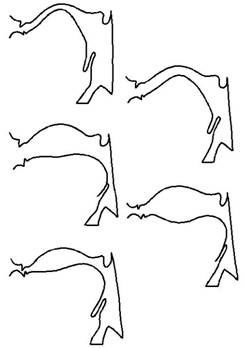
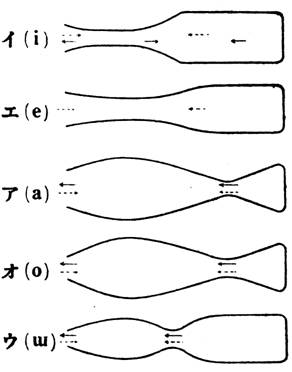
(Adapted from Chiba and Kajiyama [1])
By producing sounds from Arai’s models, we can demonstrate the relationship between vocal-tract shape and vowel quality. The characteristics of vocal-tract shape for the five Japanese vowels are summarized as follows:
- /i/: The oral cavity has a narrow constriction whereas the pharyngeal cavity is largely opened;
- /e/: similar to /i/ but the constriction at the oral cavity is slightly wider than /i/;
- /a/: The pharyngeal cavity has a narrow constriction whereas the oral cavity is largely opened;
- /o/: It is similar to /a/ but the lip opening is narrower than /a/;
- /u/: There is a narrow constriction at the mid point of the vocal tract as well as another constriction at the lips.
[Video of the cylinder-type model /i/ and the small lung model (277 kB)]
[Video of the cylinder-type model /e/ and the small lung model (277 kB)]
[Video of the cylinder-type model /a/ and the small lung model (309 kB)]
[Video of the cylinder-type model /o/ and the small lung model (213 kB)]
[Video of the cylinder-type model /u/ and the small lung model (277 kB)]
4. Other vocal tract models
4.1 Head-shaped models
None of the models discussed so far seemed to help us visualize how the vocal tract is positioned in the head. In response to this need, we created another type of vocal tract model.


This shows head-shaped models for /i/ (left) and /a/ (right). Each of the models is made from five acrylic plates. The center (black) plate is 1-cm thick and has a schematic midsaggital cross-section for each vowel. At both sides of the center plate, there are two transparent 3 cm thick plates. These plates have holes to achieve proper area functions for the vocal-tract configurations of the vowels /i/ and /a/, with nasal cavities. The outer-layered plates are 1-cm thick and also transparent, so that the midsaggital cross-section is visible from the outside. The velum is made of rubber and may be rotated around a pivot located at the boundary of the soft and hard palates. This movable velum acts as the velopharyngeal port and allows us to simulate nasal coupling. The velopharyngeal opening is controlled by the rotating valve.
[Video of the head-shaped model /i/ and the large lung model (754 kB)]
[Video of the head-shaped model /a/ and the large lung model (850 kB)]
4.2 Umeda and Teranishi’s model
Umeda and Teranishi (1966) made a simple device that acoustically simulates the human vocal tract [20]. One can change the cross-sectional areas of their model by moving 10-mm (or 15-mm) thick plastic strips, closely inserted from one side. The model has a nasal branch as well.
Various vowels and other sustained sounds may be produced dependent upon the configuration of the model. Glottal sounds are sent into the glottis end of the model and emitted from the mouth end. The driving unit of a horn speaker was used as a sound source. By using the model, Umeda and Teranishi investigated phonemic and vocal features of speech [20].

5. Summary
We have showed various types of physical models of the human vocal tract. We confirmed that physical models, when used in a classroom environment, are particularly effective for increasing student understanding of the theories of speech production. The combination of the lung models, artificial larynx, Arai’s cylinder-type and plate-type models, Umeda and Teranishi’s model, and the head-shaped models with nasal cavities provides the basis for an effective, comprehensive education in speech production. The models are well suited to the focus of this museum. We hope our vocal tract models will spread widely throughout the world in an effort to promote education in acoustics and science.
- T. Chiba and M. Kajiyama, The Vowel, Its Nature and Structure, Tokyo-Kaiseikan, 1942.
- T. Arai, “The replication of Chiba and Kajiyama’s mechanical models of the human vocal cavity,” Journal of the Phonetic Society of Japan, Vol. 5, No. 2, pp. 31-38, 2001.
- E. Maeda, N. Usuki, T. Arai, N. Saika and Y. Murahara, “Comparing the characteristics of the plate and clynder type vocal tract models,” Acoustical Science and Technology, Vol. 25, No. 1, 2004.
- T. Arai, N. Usuki and Y. Murahara, “Prototype of a vocal-tract model for vowel production designed for education in speech science,” Proc. of the 7th European Conf. on Speech Communication and Technology, Vol. 4, pp. 2791-2794, Aalborg, 2001.
- T. Arai, “An effective method for education in acoustics and speech science: Integrating textbooks, computer simulation and physical models,” Proc. of the Forum Acusticum Sevilla, 2002.
- N. Saika, E. Maeda, N. Usuki, T. Arai and Y. Murahara, “Developing mechanical models of the human vocal tract for education in speech science,” Proc. of the Forum Acusticum Sevilla, 2002.
- E. Maeda, N. Usuki, T. Arai and Y. Murahara, “The importance of physical models of the human vocal tract for education in acoustics in the digital era,” Proc. of China-Japan Joint Conference on Acoustics, pp. 163-166, Nanjing, 2002.
- T. Arai, E. Maeda, N. Saika and Y. Murahara, “Physical models of the human vocal tract as tools for education in acoustics,” Proc. of the First Pan-American/Iberian Meeting on Acoustics, Cancun, 2002.
- E. Maeda, T. Arai, N. Saika and Y. Murahara, “Lab experiment using physical models of the human vocal tract for high-school students,” Proc. of the First Pan-American/Iberian Meeting on Acoustics, Cancun, 2002.
- T. Arai, “Physical and computer-based tools for teaching Phonetics,” Proc. of the International Congress of Phonetic Sciences, Vol. 1, pp. 305-308, Barcelona, 2003.
- T. Lander and T. Arai, “Using Arai’s vocal tract models for education in Phonetics,” Proc. of the International Congress of Phonetic Sciences, Vol. 1, pp. 317-320, Barcelona, 2003.
- N. Usuki, T. Arai and Y. Murahara, “Prototype of vocal-tract models for education in acoustics of vowel production,” Proc. Spring Meet. Acoust. Soc. Jpn., Vol. 1, pp. 399-400, 2001 (in Japanese).
- N. Usuki, M. Yoshida, Hasan A. Alwi, T. Arai and Y. Murahara, “Usefulness of a mechanical model of the human vocal tract for education in speech science: Perturbation theory in vowel production,” Proc. Autumn Meet. Acoust. Soc. Jpn., Vol. 1, pp. 403-404, 2001 (in Japanese).
- T. Arai, “Incorporating more intuitive acoustic education into speech science,” Proc. Spring Meet. Acoust. Soc. Jpn., Vol. 2, pp. 1219-1220, 2002 (in Japanese).
- E. Maeda, T. Arai, N. Saika and Y. Murahara, “Education in acoustics using mechanical models of the human vocal tract in high school,” Proc. Autumn Meet. Acoust. Soc. Jpn., Vol. 1, pp. 299-300, 2002 (in Japanese).
- T. Arai, N. Saika, E. Maeda and Y. Murahara, “Chiba-Kajiyama ni yoru seidou-mokei no fukugen to sono kyouzai to shite no ouyou,” Proc. of the General Meeting of the Phonetic Society of Japan, pp. 23-28, 2002 (in Japanese).
- T. Arai and E. Maeda, “Acoustics education in speech science using physical models of the human vocal tract,” Trans. Tech. Comm. Education in Acoustics, The Acoustical Society of Japan, Vol. EDU-2003-08, pp. 1-5, 2003 (in Japanese).
- E. Maeda and T. Arai, “Education in acoustics for high-school students using mechanical vocal tract,” Trans. Tech. Comm. Education in Acoustics, The Acoustical Society of Japan, Vol. EDU-2003-09, pp. 1-6, 2003 (in Japanese).
- E. Maeda, T. Arai, N. Saika and Y. Murahara, “Studying the sound source of a mechanical vocal tract using a driver unit of horn speaker,” Proc. Spring Meet. Acoust. Soc. Jpn., Vol. 1, pp. 417-418, 2003 (in Japanese).
- T. Arai, E. Maeda and N. Umeda, “Education in Acoustics using Umeda and Teranishi’s mechanical model of the human vocal tract,” Proc. Autumn Meet. Acoust. Soc. Jpn., Vol. 1, pp. 341-342, 2003 (in Japanese).
- K. N. Stevens, Acoustic Phonetics, MIT Press, 1998.
- T. Arai, “Education in Acoustics using physical models of the human vocal tract,” Proc. International Congress on Acoustics, Vol. III, pp. 1969-1972, Kyoto, 2004.
- T. Arai, “Visualizing vowel-production mechanism using simple education tools,” J. Acoust. Soc. Am., Vol. 118, No. 3, Pt. 2, p. 1862, 2005.
- T. Arai, “Lung model and head-shaped model with visible vocal tract as educational tools in Acoustics,” Proc. Spring Meet. Acoust. Soc. Jpn., Vol. 1, pp. 273-274, 2005 (in Japanese).
- T. Arai, “Sliding three-tube model as a simple educational tool for vowel production,” Acoustical Science and Technology, Vol. 27, No. 6, pp. 384-388, 2006.